Fixing over 400 TypeScript errors
I contribute to a React client written mostly in TypeScript.
Unfortunately, when I joined the team there were over 400 type errors in this code repository.

I spent some time thinking about our options to eliminate these errors.
- We could create Jira tickets up front and prioritize the tech debt pay down with our Product team.
- We could configure a separate TypeScript build that only includes files with no type errors, add files to the list as we fix errors and add the error-free build step to CI.
- We could have our cake and eat it too.
Create Jira tickets and prioritize
The problem with this approach is the time it would take.
Engineers would have investigate the codebase to identify a logical ticket breakdown. Then we would have to create tickets. Then we would have to groom the tickets. Then we would have to point the tickets. Then we would have to prioritize the tickets.
I'll say it... most of the time, fixing bugs and building features gets priority over addressing tech debt. That's just the way the cookie crumbles.
What's more, we already had technical debt tickets which were yet to be brought into a sprint. These were higher priority than any type fix tickets we would create.
Even if this new work was top priority, that's a lot of time.
Configure a separate TypeScript build for CI
The inspiration for this strategy came from a couple resources my teammate shared. I was hoping to link the resources here. Unfortunately, I gave it the ole college try but couldn't find them.
Advantages:
- Incrementally fix all the errors without taking a lot of time away from product enhancements.
- Ensure no new type errors make it into passing files.
- No need to create a bunch of tickets to prioritize.
- Some tickets would still need to be created for large efforts but much less than option #1 above.
Disadvantages:
- This would introduce overhead when adding, deleting and re-organizing files.
- Team would need discipline to recognize when files had type errors and to fix the errors.
- Not saying that we weren't a disciplined crew. We definitely could have come to an agreement and trusted each other to do our best. But I am saying the last thing we needed was something else to manually keep track of.
- We would need to maintain two build configs.
- The error-free config would need to be a complete dependency graph of files without type errors in order for the build to pass.
What we decided
After thinking about this for a while I submitted a small proposal PR to type check only our staged files before we could successfully commit them.
This way, we could incrementally pay down the tech debt as we pushed the product forward. We would ensure that no new type errors were introduced in the files we were modifying without the manual overhead of managing file paths in a tsconfig.
As we shipped features and squashed bugs we were leaving the campground cleaner than we found it.
How to set this up
To accomplish this we used the lint-staged NPM package to run linter checks only on our staged files.
We used the eslint-plugin-tsc NPM package to wrap our TypeScript compiler checks in a linter rule.
We enforced the linter rule on our staged files by configuring lint-staged in our package.json file as well as configuring our pre-commit hook to run lint-staged.
{..."lint-staged": {"src/**/*.{ts,tsx}": "eslint --plugin tsc --rule 'tsc/config: [2, {configFile: \"./tsconfig.json\"}]'"}...}
We used husky to invoke pre-commit hooks. In our .husky/pre-commit file:
#!/bin/sh. "$(dirname "$0")/_/husky.sh"npx lint-staged
This way, only staged files were checked for TypeScript errors when committing code. A type error detected in the staged files would prevent the staged code from being committed.
Nothing is perfect, what gives?
Our strategy was not without downsides.
Type fixes could break other types
We had no automated checks to know when the type fixes in one file caused new type errors in other files.
In retrospect we could've written a CI script to compare the number of typescript errors before the changes to the number of errors after the changes.
Then we could've failed the CI pipeline when new errors were introduced.
Time overhead
Another point of friction was the overhead of developers addressing type errors in areas of files they weren't intending to edit. Time was taken away from their task to debug (oftentimes someone else's) type errors.
To time-box this, we decided that if fixing type errors unrelated to our changes took over 30 minutes then the dev would create a Jira ticket to capture that work and skip the type checks for those files.
This actually worked out nicely because after 30 minutes the developer usually had a decent understanding of the issue as well as a path forward. The details were top-of-mind when they were captured in the Jira ticket.
We worked with Product to prioritize new tickets as they were written. This planning made the entire team aware of where our complex type errors lived.
The results
Even considering the downsides, this strategy was the best path forward for our team.
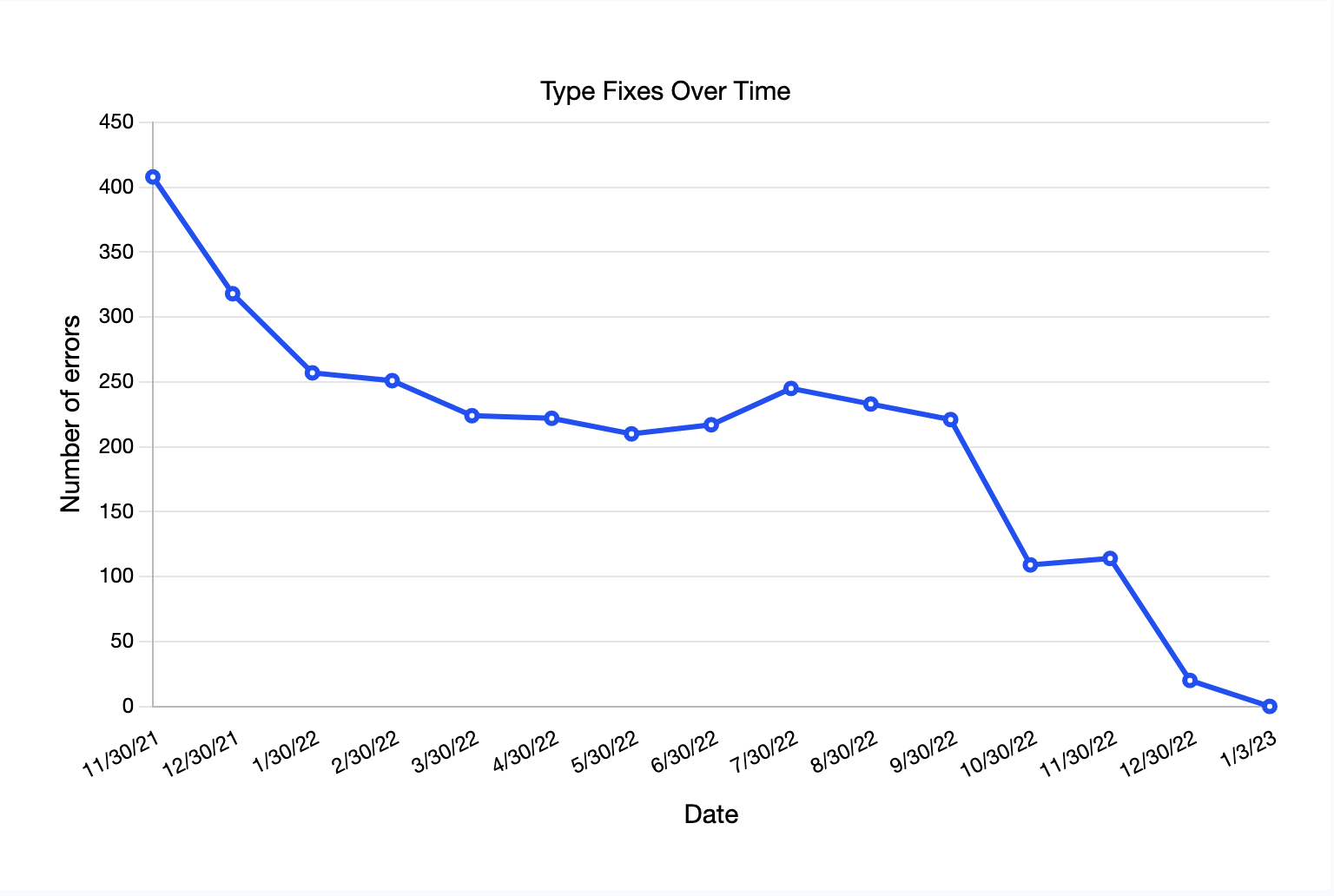
| Date | Type Error Count |
|---|---|
| 11/30/21 | 408 |
| 12/30/21 | 318 |
| 1/30/22 | 257 |
| 2/30/22 | 251 |
| 3/30/22 | 224 |
| 4/30/22 | 222 |
| 5/30/22 | 210 |
| 6/30/22 | 217 |
| 7/30/22 | 245 |
| 8/30/22 | 233 |
| 9/30/22 | 221 |
| 10/30/22 | 109 |
| 11/30/22 | 114 |
| 12/30/22 | 20 |
| 1/3/23 | 0 |
For the most part, we consistently reduced the number of errors month over month (with the exception of 3 months).
We had no automated checks to know when the type fixes in one file caused new type errors in other files.
This is why you can see the number of type errors increase during periods of heavy development.
As we were closing in on 100 total type errors in the source code, it was time to create a Jira ticket to fix the rest all at once. The final push also included the addition of an automated CI check to ensure no new code could be merged with type errors.
The strategy we used may not be the best approach for all teams but it worked quite well for us.